以Web代理劫持会话绕过并破解网页版软件USB-Key加密狗方案
提醒:本页面将不再更新、维护或者支持,文章、评论所叙述内容存在时效性,涉及技术细节或者软件使用方面不保证能够完全有效可操作,请谨慎参考!
单位某信息管理系统,需要加密狗才能运行,因为加密狗只有一个,该系统又需要维护各部门台账信息,遂思考在不增加加密狗的情况下能否将该系统分发下去,已知该系统采用Java Web方式编写,虽然有桌面应用的样子,但实质上是Web应用,很容易找到了Java Web服务器和实际的访问URL,在防火墙端口开放访问,并在路由器上做好端口映射,其他电脑访问正常,本来以为万事大吉,哪知道在登录的时候客户端提示没有加密狗无法登录。
审阅了登录页面的源代码,发现其采用ActiveX控件方式读取加密狗并设置登录信息以便于提交服务器,客户端没有加密狗,这个验证肯定也无法通过,原来我一直以为这个软件的加密狗是用于服务器端的,没想到客户端网页也采用了加密狗保护机制。
通常意义上加密狗是一种软件保护机制,主要防止软件被盗版,其通过硬件的方式保护核心的算法(比如关键公式),在软件需要的时候由硬件进行数据处理以完成整个软件流程,那么可以知道其登录信息的加密方式是存储在加密狗里面的,如果要登录成功又必须需要加密后的登录凭证。
因为该软件项目规模较大,反编译修改软件较为复杂,而且领导明确要求不可以改动原软件,所以只有另行他法。
已知我们现在有一正常工作的加密狗,为什么不直接借助该加密狗进行验证,再将验证数据代理提交呢?这里衍生出第一套方案,采用在有加密狗的服务器上私设反向代理Web服务器,并编写简单的登录页面,当用户使用该页面登录的时候我们获取到用户名和密码,再使用加密狗进行运算,最后将结果提交给真实的Java Web服务器,最后获取到Session会话的Cookie,再一次的将该Cookie使用Set-Cookie返回给用户,这样客户端用户相当于劫持了原来私设Web服务器与真实Java Web服务器的会话,然后成功登录。
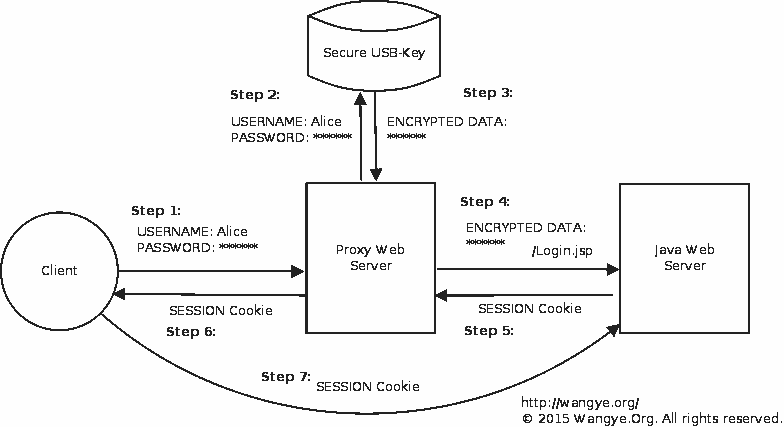
这种方式要成功有个关键,那就是处于同一域名下(跨域名如果要成功主要要考虑Cookie跨站等因素),最好的状态是直接借助真实的Java Web服务器,设置新的登录页面,只不过将加密狗验证放在服务器端完成,这样可行性更高,也避免Cookie受到反XSS机制的干扰。
提到自己搭建Web服务器可能大家会想到使用IIS、Apache等,其实这里并不需要这么麻烦,因为我只需要维护一小部分用户访问,所以使用Python的SimpleHTTPServer库即可,对于向Web Server发出请求则用到了requests库(需要安装),一个简单实现的例子如下:
# -*- coding: utf-8 -*-
import cgi
import requests
import Cookie
from BaseHTTPServer import BaseHTTPRequestHandler, HTTPServer
class ProxyRobot(object):
urls = {
"login" : "/login.jsp",
"auth" : "/login.jsp",
}
base_url = "https://wangye.org/"
headers = {
"User-Agent" : "Mozilla/5.0 (Windows NT 6.0; WOW64; rv:15.0) Gecko/20090101 Firefox/14.0.1",
"Accept" : "text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8",
"Accept-Language" : "zh-cn,zh;q=0.8,en-us;q=0.5,en;q=0.3",
"Accept-Encoding" : "gzip,deflate",
"Connection" : "keep-alive",
"Referer" : "https://wangye.org/",
}
def post(self, url_name, data):
et = self.session.post(ProxyRobot.base_url + ProxyRobot.urls[url_name], data, headers=ProxyRobot.headers)
return et
def get(self, url_name):
et = self.session.get(ProxyRobot.base_url + ProxyRobot.urls[url_name], headers=ProxyRobot.headers)
return et
def __init__(self, username, password):
self.session = requests.Session()
self.credentials = {"username" : username, "password" : password}
def _prepareLogin(self):
request = self.get("login")
# Modify something
self.credentials["testcookie"] = 1
return request.text
def login(self):
self._prepareLogin()
payload = {
"log" : self.credentials["username"],
"pwd" : self.credentials["password"],
}
request = self.post("auth", data=payload)
print request.text
def getCookies(self):
C = Cookie.SimpleCookie(self.session.cookies.get_dict())
#cookies = self.session.cookies.get_dict()
#for k,v in cookies.items():
# C[k] = v
return C
class CustomHTTPRequestHandler(BaseHTTPRequestHandler):
def getPostVars(self):
ctype, pdict = cgi.parse_header(self.headers.getheader('content-type'))
if ctype == 'multipart/form-data':
postvars = cgi.parse_multipart(self.rfile, pdict)
elif ctype == 'application/x-www-form-urlencoded':
length = int(self.headers.getheader('content-length'))
postvars = cgi.parse_qs(self.rfile.read(length), keep_blank_values=1)
else:
postvars = {}
return postvars
def send_page_header(self):
self.send_response(200)
self.send_header('Content-type', 'text/html')
def send_redirect_header(self, url):
self.send_response(302)
self.send_header("Location", url)
def do_POST(self):
self.send_page_header()
postvars = self.getPostVars()
username = postvars.get("log", ['',])[0]
password = postvars.get("pwd", ['',])[0]
robot = ProxyRobot(username=username, password=password)
robot.login()
cookies = robot.getCookies()
self.wfile.write(cookies.output())
self.end_headers()
def do_GET(self):
self.send_page_header()
self.end_headers()
self.wfile.write("<html>\r\n<head><title>Login Gateway</title></head><body>\r\n")
self.wfile.write("""
<form action="" method="POST">
Username: <input type="text" name="log" /> <br /><br />
Password: <input type="password" name="pwd" /> <br /> <br />
<input type="submit" value="Click to Login" />
</form>
""")
self.wfile.write("\r\n</body></html>")
class CustomHTTPServer(HTTPServer):
def __init__(self, host, port):
HTTPServer.__init__(self, (host, port), CustomHTTPRequestHandler)
def main():
server = CustomHTTPServer('127.0.0.1', 8000)
server.serve_forever()
if __name__ == '__main__':
main()事实上我并没有采用上述的方法,因为不知道是什么原因Cookie经常获取不到,所以这里又提到了第二套方案,Plan B计划则采用稳妥方式,将验证交还给客户端,服务器端只保留加密狗验证功能,即接受客户端提交的用户名和密码由加密狗运算得到加密数据,将数据反馈给客户端,客户端再次持该加密数据提交给真实的Java Web服务器端进行验证,成功后就一路绿灯了,这种方式的稳定性和隐蔽性较高,对于Java Web服务器来说实际上仍然和真实的客户端进行数据交换。
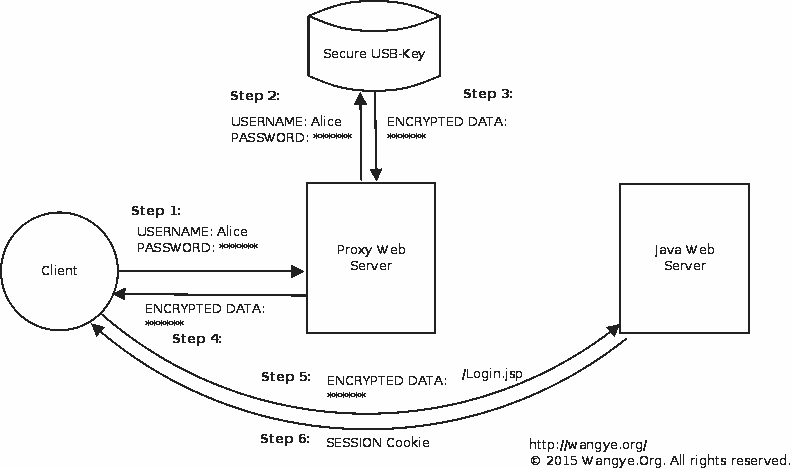
对于Python代理服务器端调用加密狗的方式可以采用ActiveX,具体参考PyWin32的
Dispatch
和
DispatchEx
相关。相关代码我就不贴出来了,这里有个小插曲,原来的软件不光登录页面采取了加密狗限制,甚至连登录后的页面都要验证加密狗,好在其登录后的页面主要加载了一个Flash(不得不吐槽一下该软件大部分由Flash构成),更奇葩的是其在每一次点击Flash子栏目的时候会发起一个检查加密狗是否正常的请求,要不是领导要求不能破坏软件,我都想直接屏蔽掉这个加密狗检查请求了,事实也证明是可以做到的,最后我把登录后的页面另存了一份修改页到我搭建的Python Web服务器下,然后加密狗数据请求部分再次使用Python调用服务器端加密狗获取,也算维护了整体软件的完整吧,具体的代码我就不贴了,以上思路仅供参考。
厉害! 特意留言!