网页HTML中电子邮箱(Email)地址的加密和混淆防采集
提醒:本页面将不再更新、维护或者支持,文章、评论所叙述内容存在时效性,涉及技术细节或者软件使用方面不保证能够完全有效可操作,请谨慎参考!
邮箱里垃圾邮件一直有很多,这让我不得不重新审视,发布在网页上的电子邮箱地址,为了避免垃圾邮件,我刻意将
@
更换成
#
,也许这在十年前是个不错的办法,但是随着神经网络和机器学习新算法的发展,这一类小手段也面临失效的风险,因为大部分都是通过修改电子邮箱地址的“@”符号,通过正则表达式筛选和特征值匹配,比如hotmail.com、gmail.com、163.com这一类疑似电子邮箱地址的特征,还是可以抓取到电子邮箱地址,所以在将Email发布到HTML网页之前我们要对其进行加密和混淆。
下面我以[email protected]为例,介绍几种加密和混淆的反垃圾邮件手段。
1. 生成图片
利用传统的图灵测试CAPTCHA,将防止采集的电子邮箱地址生成图片,利用机器不能识别的特性,来区别人和机器,生成图片的方式有很多,除了高大上的Photoshop外,甚至可以使用系统自带的绘图工具来完成,另外希望偷懒的话,还有一些在线工具可以帮助到你,比如 《Top 10 Websites to Turn Your Email Address into An Image》 。
当然生成图片也不是万无一失的,有理由相信既然基于图片的验证码能够被机器识别破解,那么基于同样技术的电子邮件地址肯定也再所难免,特别是OCR技术的逐步发展和成熟,采集程序可以对整张网页进行OCR,最后提取需要的内容,所以我们还需要对图片生成的邮箱地址进行噪点、干扰线等混淆,具体可以参考有关如何防止验证码被识别的相关内容。
但是经过这么一设计,我们的邮箱地址对于真正需要的人来说则变得不那么友好,人们获取准确邮箱地址的难度也加大了。
2、替换关键符号
我们知道爬虫抓取电子邮箱地址很多都是通过
@
这个特征符号,正如我文章一开头所述,将这个符号替换成别的那么将大大降低我们电子邮箱被抓取的概率,当然这样做的坏处是除非给用户以暗示,否则需要另外说明这是个电子邮箱地址,比如john#example.com又或者john{a}example.com等等,当然智能的电子邮箱抓取软件可以对这些小把戏自动免疫,通过判断域名也可以得到这是个电子邮箱地址,所以说将@替换成一个很特别的符号也是一种生存之道,对于这种替换手段来说,更有甚者将邮箱地址变成句子,比如john AT example DOT com,这样看来应该更安全了,但是也给真正需要这个电子邮箱地址的用户带来了少许困扰。
3、使用JavaScript
JavaScript简称JS通常作为嵌入到网页的一段小脚本,为其提供更为丰富的交互和应用,我们通过JS混淆我们的电子邮箱地址,最后再用document.write或者innerHTML等输出来,这样的好处是绝大多数爬虫并不能执行网页里的脚本,它们只擅长抓取静态文本,所以完全不必担心邮箱地址泄露给爬虫,另外对于最终用户来说,通过浏览器的解释,展现在他们面前的全是一个完整的电子邮箱地址,用户体验好,不过这种方式有个较为致命的弱点就是如果用户浏览器不支持脚本,那么邮箱地址也就不能正常显示了,虽然这种情况不多见。
一个典型的例子如下,当然有很多变形的实现,比如 PHP hide_email 我这里也不多介绍了。
var username = "john";
var hostname = "example.com";
document.write(username + "@" + hostname);尤其值得一提的是ROT13算法的应用,ROT13即回转13位,说到底就是将字母表首位衔接成环,将待编码字母映射到其旋转的13位的字母上,如下示意图所示:
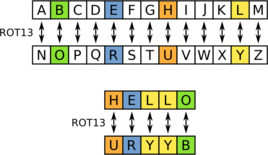
对于PHP来说,有函数 str_rot13 可以直接使用,然后根据其算法反转即可得到加密前的文本,一般使用如下JS代码:
<script type="text/javascript">document.write("<n uers=\"znvygb:[email protected]\" ery=\"absbyybj\">Fraq n zrffntr</n>".replace(/[a-zA-Z]/g,
function(c){return String.fromCharCode((c<="Z"?90:122)>=(c=c.charCodeAt(0)+13)?c:c-26);}));
</script>上述代码将解码成以下HTML:
<a href="mailto:[email protected]" rel="nofollow">Send a message</a>4、使用HTML和CSS混淆
当然我们除了采用JavaScript,还可以利用HTML或者CSS的一些小技巧(tricks),使用HTML注释混淆,在HTML中以
<!--
和
-->
包含的是注释,不会被浏览器渲染给最终用户,那么我们可以充分利用这一点从而将我们的电子邮件地址打造成这样的:
jo<!-- >@. -->hn@<!-- >@. -->exam<!-- >@. -->ple.com
这里
<!-- >@. -->
不会被浏览器显示,但是足以混淆机器爬虫的抓取。
同样的结合CSS的
display:none
,我们仍然可以得到以下类似手段的混淆:
jo<span style="display:none">@</span>hn@<span style="display:none">@</span>exam<span style="display:none">@</span>ple.com
同样的CSS的
display:none
必然注定了其包含的文本不会被显示,所以最终显示的也是完整的电子邮箱地址。
对于CSS来说还有一种办法也可以让我们规避爬虫抓取,那就是利用CSS文本显示顺序的特点,比如以下:
<span class="obfuscate">moc.noitpecni@kcik</span>其中CSS代码如下:
.obfuscate { unicode-bidi: bidi-override; direction: rtl; }首先文本是被我们逆序的,如果要还原,在不借助JS的情况下可以通过CSS将其再次逆序,从而得到正确的文本,当然这个方法我试用下来有一点不足,那就是用户选择复制电子邮箱地址仍然是逆序的。
最后总结来看,在对抗垃圾邮件爬虫收集的方法上充分发挥了网友的聪明才智,也涌现出各种有才的实现,限于篇幅我也不一一介绍了,其实没有绝对的安全,最安全的办法就是没有电子邮箱地址,此话怎讲?那就是使用联系表单(Contact From),让需要和你联系的人直接通过表单和你发邮件,从而避免了电子邮件地址的公开,网上联系表单的开源代码也有一堆,我的博客最后考虑的方式也是这个,现在大家可以通过右上角“关于我”找到这个链接并给我发消息了。
参考资料
上午生成图片的链接地址挂了
没有挂,可能Broken Link Checker插件检查不了HTTPS,全部被划去了。
学习了,没想到这么多混淆email的方法,PHP hide_email的还不错哦。